現在の投稿数 177

Bữa ăn hôm nay là gì ?!

【Python 雑談・雑学 + coding challenge】Python data structure の1つ、set を活用していますか? 複数のシーケンスの包含関係を調べるには最適です 投稿一覧へ戻る
Published 2020年8月11日21:03 by mootaro23
SUPPORT UKRAINE
- Your indifference to the act of cruelty can thrive rogue nations like Russia -
まずはご自分でコーディングにチャレンジ ( coding challenge ) してみて下さい。
問題 ( 制限時間: 25 分 ):
1 行に 1 つの単語が記述されているテキストファイルを用意します。
こちら のファイルを利用させていただくことも可能です。23 万 5 千行あります。
用意したファイルを読み込み 1 行 1 行読みながら、a, e, i, o, u という母音を全て含んでいる単語だけを要素とするリストを作成してください。
やるべきこと自体はそれほど複雑ではありませんね。
ファイルを開き 1 行ずつ読み込みます ( 1 行 1 単語ですから、行 == 単語 として処理可能です)。
a, e, i, o, u を 1 文字ずつループして、それが取り出した単語に含まれているか判断し、全てが含まれていればリストに加えます。
これで全然問題ありません。
ただし今回の問題をデータ構造の観点から考えてみると、a, e, i, o, u という「母音の集合」を、ファイルから取り出した単語を構成する「文字の集合」がすべて含んでいれば良いわけです。
そして Python には「集合」を効率よく扱うためのデータ構造 ( data structure ) が標準でちゃんと用意されています、そうです、set です。
そこで、set と list comprehension を活用して先程のコードを書き換えてみましょう。
1: set として定義しています。
2: 単語 ( 文字列 ) もシーケンスですから、set() に渡すことで、「重複のない文字の集合」を取得できます。
set1 >= set2 という比較で、set1 という集合が set2 という集合を部分的に含んでいるか、もしくは、set2 という集合と等しいか、を調べ、
その結果が True であれば、
3: 末尾に改行文字 ( '\n' ) が付いているため、それを除去してからリストに追加します。
どちらが良い、というわけではありませんが、Python 的なのは後者だと思います。
list, tuple, dict, set 等の組み込みのデータ構造を活用することでクラスを記述することなく簡潔で処理も速いコードが記述できる場面も多々ありますよね。
問題 ( 制限時間: 25 分 ):
1 行に 1 つの単語が記述されているテキストファイルを用意します。
こちら のファイルを利用させていただくことも可能です。23 万 5 千行あります。
用意したファイルを読み込み 1 行 1 行読みながら、a, e, i, o, u という母音を全て含んでいる単語だけを要素とするリストを作成してください。
def get_super_vocalic(file_name):
pass
pass
やるべきこと自体はそれほど複雑ではありませんね。
ファイルを開き 1 行ずつ読み込みます ( 1 行 1 単語ですから、行 == 単語 として処理可能です)。
a, e, i, o, u を 1 文字ずつループして、それが取り出した単語に含まれているか判断し、全てが含まれていればリストに加えます。
def get_super_vocalic(file_name):
vowels = ['a', 'e', 'i', 'o', 'u']
result = []
with open(file_name, encoding='utf-8') as f:
for word in f:
for vowel in vowels:
if vowel not in word.lower():
# 含まれていない母音があればこの単語はリストには追加しません
break
else:
# 全ての母音が含まれていれば、文字列の最後に含まれている改行文字 '\n' を除去してリストに加えます
result.append(word.strip())
return result
data = get_super_vocalic('words.txt')
print(len(data))
# 6004
print(data)
# ['abevacuation', 'abietineous', ..., 'zomotherapeutic', 'Zonuridae']
vowels = ['a', 'e', 'i', 'o', 'u']
result = []
with open(file_name, encoding='utf-8') as f:
for word in f:
for vowel in vowels:
if vowel not in word.lower():
# 含まれていない母音があればこの単語はリストには追加しません
break
else:
# 全ての母音が含まれていれば、文字列の最後に含まれている改行文字 '\n' を除去してリストに加えます
result.append(word.strip())
return result
data = get_super_vocalic('words.txt')
print(len(data))
# 6004
print(data)
# ['abevacuation', 'abietineous', ..., 'zomotherapeutic', 'Zonuridae']
これで全然問題ありません。
ただし今回の問題をデータ構造の観点から考えてみると、a, e, i, o, u という「母音の集合」を、ファイルから取り出した単語を構成する「文字の集合」がすべて含んでいれば良いわけです。
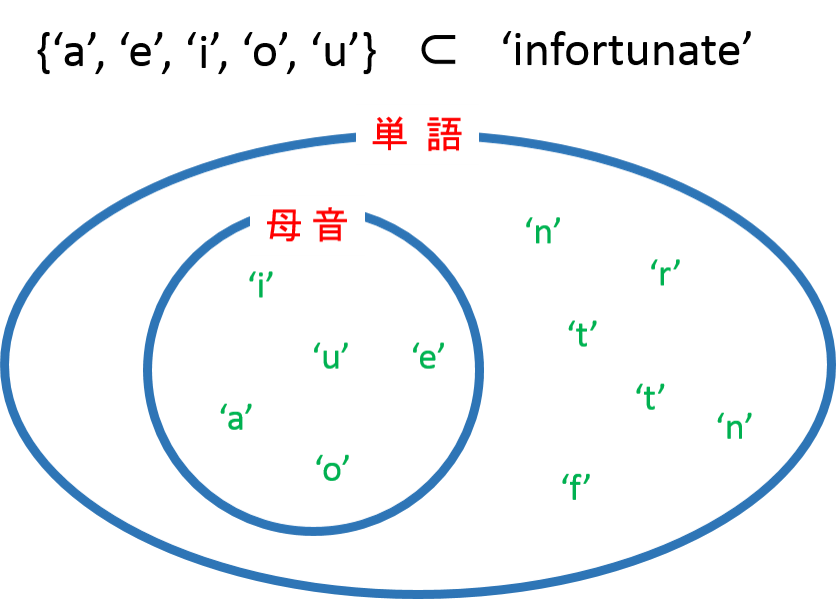
そして Python には「集合」を効率よく扱うためのデータ構造 ( data structure ) が標準でちゃんと用意されています、そうです、set です。
そこで、set と list comprehension を活用して先程のコードを書き換えてみましょう。
def get_super_vocalic_using_set(file_name):
vowels = {'a', 'e', 'i', 'o', 'u'} # 1:
with open(file_name, encoding='utf-8') as f:
return [line.strip() # 3:
for line in f
if set(line.lower()) >= vowels] # 2:
vowels = {'a', 'e', 'i', 'o', 'u'} # 1:
with open(file_name, encoding='utf-8') as f:
return [line.strip() # 3:
for line in f
if set(line.lower()) >= vowels] # 2:
1: set として定義しています。
2: 単語 ( 文字列 ) もシーケンスですから、set() に渡すことで、「重複のない文字の集合」を取得できます。
set1 >= set2 という比較で、set1 という集合が set2 という集合を部分的に含んでいるか、もしくは、set2 という集合と等しいか、を調べ、
その結果が True であれば、
3: 末尾に改行文字 ( '\n' ) が付いているため、それを除去してからリストに追加します。
どちらが良い、というわけではありませんが、Python 的なのは後者だと思います。
list, tuple, dict, set 等の組み込みのデータ構造を活用することでクラスを記述することなく簡潔で処理も速いコードが記述できる場面も多々ありますよね。
この記事に興味のある方は次の記事にも関心を持っているようです...
- People who read this article may also be interested in following articles ... -