「WSGI サーバーのセットアップ part 2: Postman を利用した API エンドポイントのテスト」の巻
サーバーが機能しウェブサイトを提供できることを確認しましょう。次のスクリプトは
uWSGI のドキュメンテーションサイト に掲載されている例で、レスポンスとしてステータスコード 200 と body として 'Hello World' というメッセージを返すサーバーアプリケーションを実装するものです:
def application(env, start_response):
start_response('200 OK', [('Content-Type', 'text/html')])
return [b'Hello World']
上記のファイルを仮想環境のルートディレクトリに置き仮想環境に入っている状態で以下のコマンドを打ち込んで、hello_world_server.py がリクエストを処理するアプリケーションとして設定されたサーバーを立ち上げます:
uwsgi --http :9090 --wsgi-file hello_world_server.py
ブラウザを立ち上げてアドレスバーに http://localhost:9090 を打ち込んでリクエストを送信してください。ブラウザの画面に 'Hello World' と表示されればウェブサーバーが正常に稼働しています。Ctrl + c でサーバーを終了できます。
Congratulations! ご自身のウェブサーバーの運営に成功しました!これで全世界に向けてウェブサイトを公開し URL によるリクエストを受け付けることができます。次に為すべきことは、一からミドルウェアを構築し、リクエストを受け付けレスポンスを返す、という流れの中にどのように埋め込まれているのか、を確認することです。
既にサーバーの稼働には成功していますから、リクエストヘッダーにユーザートークンが含まれているかどうかをチェックする関数を追加しましょう。この際、オンラインで見かけるより大規模な API で採用されている規則に従いたいと思います。
クライアントが「許可」が必要なリソースにアクセスしたい場合、Authorization ヘッダーに認証情報を含めることになります。一般的な Basic 認証の場合、その認証情報は「'Basic' + スペース + BASE64 エンコードされた文字列」というフォーマットです。そして、BASE64 エンコードされる文字列は「ユーザー名:パスワード」というフォーマットになります。この情報によってサーバー側ではユーザーを認識し、リソースへのアクセス許可・拒否を決定するわけです。
機能の実装に取り掛かる前にもう一度整理しておきます。ウェブサーバーのアプリケーションにアクセスする際に認証情報 (Authentication header) を含め、ミドルウェアでこの情報をチェックし、認証情報の代わりに該当するユーザーの User object をリクエストに含ませるようにすれば、アプリケーション側では認証情報等の解析処理を一切伴わずに該当リソースに対するアクセス制限やユーザー固有の処理を行うことができる、ということです。
さて、ある URL エンドポイントとのやり取りをテストする最も簡単な方法は Postman のような外部ツールを利用することです。こういったツールからテストしたいエンドポイントに対してリクエストを送信し、それに対するレスポンスをチェックすることができます。Postman のダウンロードは
https://www.postman.com/ から行えます。
ここからは Postman を利用して我々のアプリケーションをテストします。
uWSGI サーバーと Postman を立ち上げます。リクエスト種別が GET になっていることを確認し、アドレスバーに http://localhost:9090/ を入力して Send ボタンをクリックしてください。画面右下のセクションに Hello World と表示されれば、サーバー上のアプリケーションも Postman も正常に動作しています:
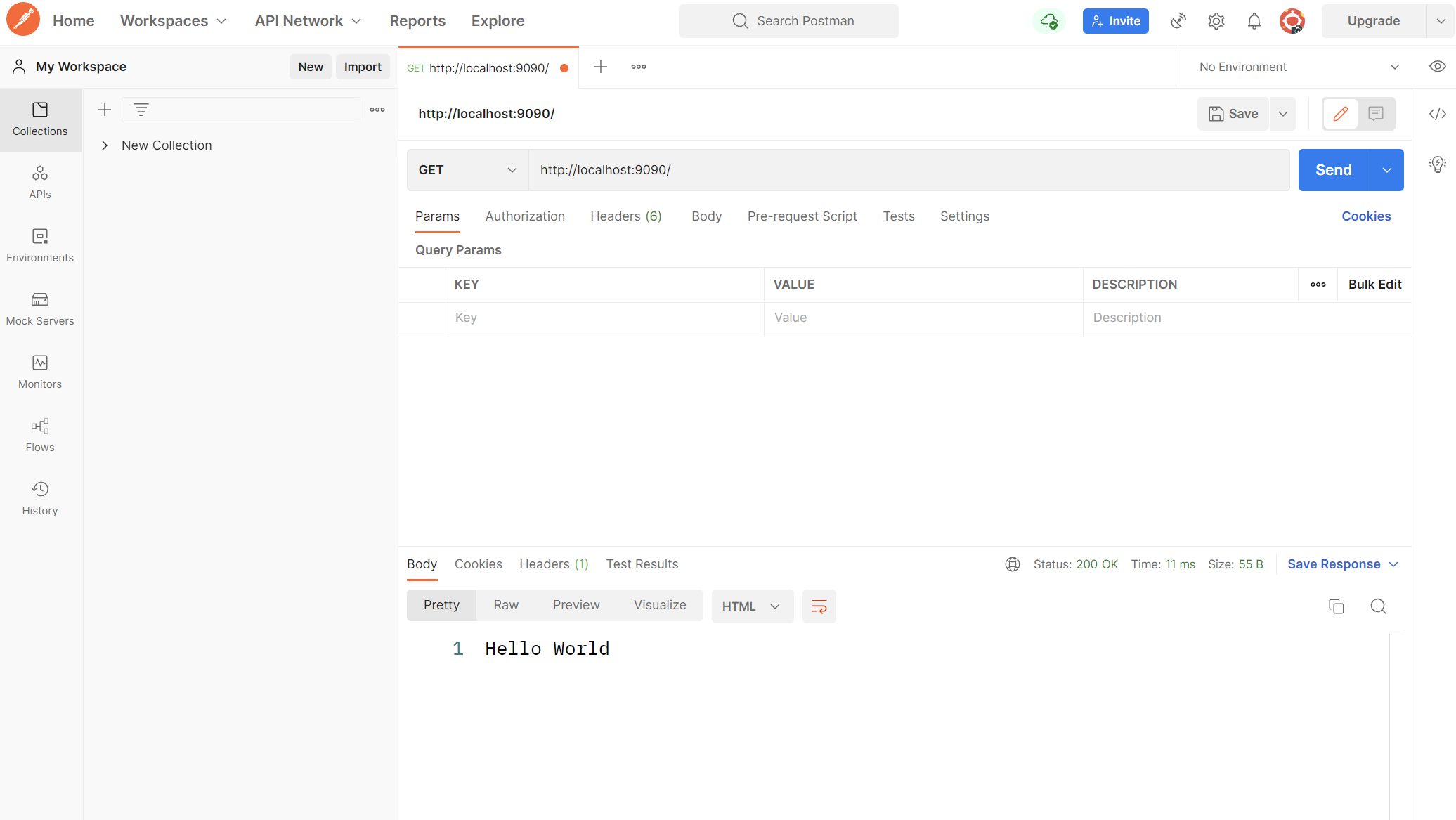
Postman を利用した API エンドポイントのテスト
アドレスバーの下に並んでいる複数のタブの中に Authorization タブがあります。このタブをクリックし、Type ドロップダウンボックスから Basic Auth を選択してください。Username と Password を入力するためのテキストボックスが表示されましたね。ここに情報を入力してリクエストを Send することでエンコードされた認証情報を含む Authorization ヘッダーが追加されるようになります。
この時 uWSGI から受け取る Request オブジェクトの内容を確認するために、アプリケーションの内容を少し変更します:
hello_world_request_display.py
import pprint
pp = pprint.PrettyPrinter(indent=4)
def application(env, start_response):
pp.pprint(env)
start_response('200 OK', [('Content-Type', 'text/html')])
return [b'Hello World']
pprint は Python 組み込み標準ライブラリの1つで、dictionary や list といったデータ型オブジェクトの内容を非常に見やすいフォーマットで表示してくれます。今回のように、ウェブサーバーから受け取ったリクエストオブジェクトのような複雑なデータ型をデバッグしたい際には非常に重宝します。
今回記述し直したアプリケーションを使用するために uWSGI サーバーを再起動します。Postman を使用して Authorization ヘッダーを含めるように設定したリクエストを送信してみましょう。コンソールにリクエストヘッダーの内容が表示されるはずです。この中に含まれている HTTP_AUTHORIZATION キーが Postman で入力した認証情報になります。「'Basic' + スペース + BASE64エンコード文字列」というフォーマットになっていることが分かると思います:
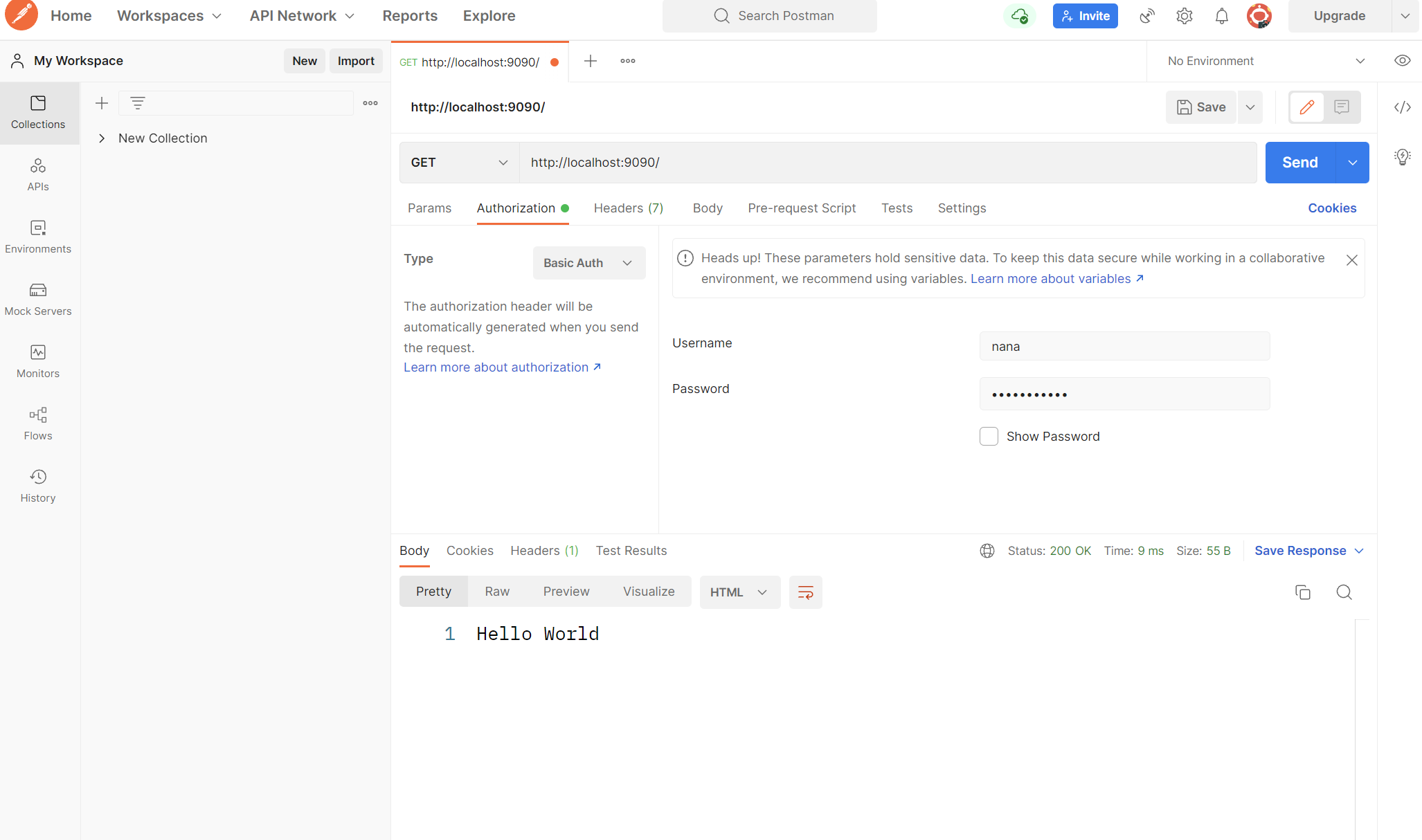
Postman を利用した Authorization ヘッダー (Basic Authentication) の追加

リクエストオブジェクトのヘッダーの内容 (HTTP_AUTHORIZATION 部分抜粋)
データベースから該当ユーザーのオブジェクトを取得するためには、エンコード文字列をデコードし username と password に分割する必要があります。さあ、アプリケーションをアップデートしましょう。
まず HTTP_AUTHORIZATION ヘッダーの値を取得します。続けて取得した文字列をスペースで分割することで、'Basic' と BASE64 エンコードされた2つの文字列を取得します。次に、BASE64 エンコードされた文字列をデコードし ':' で分割します。その結果得られるリストには、1番目の要素としてユーザー名、2番目の要素としてパスワードが入っています。最終的にこの情報を引数として取り、該当するユーザーオブジェクトをデータベースから取得する関数を実装することになるでしょうが、今回の例ではデータベースアクセス部分は省略します。興味のある方はどうぞ実際の操作の実装にチャレンジしてください:
import base64
class User:
def __init__(self, username, password, name, email):
self.username = username
self.password = password
self.name = name
self.email = email
@classmethod
def get_verified_user(cls, username, password):
return User(
username,
password,
username,
f'{username}@example.com'
)
def application(env, start_response):
authorization_header = env['HTTP_AUTHORIZATION']
header_array = authorization_header.split()
encoded_string = header_array[1]
decoded_string = base64.b64decode(encoded_string).decode('utf-8')
username, password = decoded_string.split(':')
user = User.get_verified_user(username, password)
start_response('200 OK', [('Content-Type', 'text/html')])
response = f'Hello {user.name}!'
return [response.encode('utf-8')]
この例ではリクエストに含まれる情報を「鵜呑み」にして User オブジェクトを作成していますが、この動作は明らかに間違っています。しかし、独自の User クラスを定義しアプリケーション本体とは分離していますから、クラスメソッドとして定義した get_verified_user() を変更することは非常に簡単です。本来であれば、ユーザー名に基づいてパスワードが正しいかを検証したり、与えられたユーザーが存在しない場合の処理等を記述することになるでしょう。
さて、現時点においてさえ、サーバーのメインアプリケーション内はユーザーの認証情報をチェックするためだけのコードで溢れかえっています。これはあまり良い兆候とは言えません。この兆候が「あまり良くない」ものであることの認識が間違っていないことを確認するために、最も基本的なルーティングのためのコードもメインアプリケーション内に記述してみましょう。
このルーティングコードは、クライアントがリクエストしてきたエンドポイントの情報をヘッダーから取得し、もしこの中に 'goodbye' という文字列が含まれていれば Goodbye メッセージを、それ以外の場合は Hello メッセージをレスポンスボディとして返す、という非常に簡単なものです。
リクエストされたエンドポイントのパス情報は、ヘッダーの PATH_INFO キーの値として取得できます (hello_world_request_display.py 実行時にコンソール出力したヘッダー情報を確認してください)。PATH_INFO の値は '/' で始まり残りのパスが続いています。ここでは path 文字列を '/' で分割し、純粋な形で 'goodbye' という文字列がパス中に含まれているかをチェックします:
many_functions_in_main_application.py
import base64
from pprint import PrettyPrinter
pp = PrettyPrinter(indent=4)
class User:
def __init__(self, username, password, name, email):
self.username = username
self.password = password
self.name = name
self.email = email
@classmethod
def get_verified_user(cls, username, password):
return User(
username,
password,
username,
f'{username}@example.com'
)
def application(env, start_response):
pp.pprint(env)
authorization_header = env['HTTP_AUTHORIZATION']
header_array = authorization_header.split()
encoded_string = header_array[1]
decoded_string = base64.b64decode(encoded_string).decode('utf-8')
username, password = decoded_string.split(':')
user = User.get_verified_user(username, password)
start_response('200 OK', [('Content-Type', 'text/html')])
path = env['PATH_INFO'].split('/')
if 'goodbye' in path:
response = f'Goodbye {user.name}!'
else:
response = f'Hello {user.name}!'
return [response.encode('utf-8')]
あなたの頭の中では「警報音」がけたたましく鳴り響いているはずです。ウェブサーバーのメインアプリケーションでは現在、明らかに異なる3つの操作が実行されてしまっています。まず User オブジェクトを取得しています。続けて、クライアントがリクエストしているエンドポイントを解析し、その結果に応じてレスポンスメッセージを作成しています。最後にレスポンスメッセージをエンコードしてクライアントにレスポンスを送出しています。
リクエストが届いてからそれに対するレスポンスを返すまでの間により多くの操作を行う必要がある場合、application 関数がどれほどごちゃごちゃに複雑になってしまうか考えてみてください。つまり、この実装方法を続ける限り、コードはひたすら乱雑になっていってしまいます。
理想を言えば、1つの関数で処理するのは1つ、たった1つの操作 (機能) だけにしたいのです。

