ここでいう domain とは「取り組んでいる問題領域」を意味しています。
例えば、オンライン家具ストアを対象にしているのであれば、domain は「調達・購買」であったり、「製品デザイン」であったり、「輸送・配達」であったりするかもしれません。
システム開発者は、それぞれの domain における様々な活動(ビジネスプロセス)の効率を上げ、自動化するために努力をすることになります。
model は、ある物事を処理する際に有用な情報・手段等を表現しているものです。
例えば、誰かがあなたにボールを投げたとしたら、あなたはほぼ無意識にそのボールの挙動を予測して捕球することが可能なはずです。
それは、あなたが「物体が空間でどのような動きをするのか」という model を有しているからです。
しかし、そのボールが「光の速度」で、もしくは、「真空中」で動くとしたらどうでしょう?
あなたが有している model はそのケースに対処できるようにはなっていないかもしれません。
ただし、それはあなたの model が「ダメ」ということではありません。それは、ある domain をカバーする model であっても全てを予測可能なわけではない、ということを表しているだけです。
Domain model は、ビジネスオーナーらが彼らのビジネスに対して有している「mental map」です。
この mental map は、複雑な問題・システムに対する反応・対処の集積といえるもので、これらに関わっている人達の会話に隠語・専門用語 (jargon) が多く登場するのは自然なことでしょう。
この章で取り上げる Domain-driven design (ドメイン駆動設計) において、ドメイン専門家(ビジネスオーナー等)が提供する「専門用語・隠語」を、この domain にかかわるすべての人(ユーザー、スポンサー、開発者等)が共有できる common language (共通言語) として用意することが重要、とされています。
想像してみてください。
あなたとあなたの家族、友人は、不幸にも地球から何光年も離れた宇宙空間を不慣れな宇宙船で漂っているとします。
優先事項は、どうやって地球へ帰るか、ということですよね。
あなたは、様々なボタンを押してみることに最初の2,3日を費やすかもしれません。
でもその内、どのボタンを押すとどうなるのか、が少しずつ分かってきます。
そして他の人にそれを伝えることになります:
「なんかあの点滅してるやつのすぐそばにある赤いボタン、あれ押してから、何だあれ、あのレーダーみたいなやつの隣にある大きなレバーをガチャっとするわけ...」
しかし数週間経つうちにより「適切」な単語を使い、周りの人もそれを理解するようになり、より「正確」に宇宙船の操作と機能について「会話」できるようになっているはずです:
「カーゴ内の酸素レベルを3上げてくれ」
「軌道修正のため小型エンジンを始動しよう」
そして数ヶ月後には、一連の複雑な操作プロセスを「表現」するための「専門用語 / 隠語」を使いこなしているでしょう:
こういった流れは、それといった明らかな「努力」をするまでもなく自然と発生することです。
DDD は、domain model を実装するためのシステム設計における基本的な考え・手法を示したものです。
そこでは、ソフトウェアを設計する際には対象となるビジネスの domain にフォーカスすべきである、とされていています。
Entity (エンティティ)、Aggregate (集計パターン)、Value Object (値オブジェクト)、Repository (リポジトリ) といった多くのアーキテクチャパターン (architecture patterns) が DDD の考えから生まれています。
端的に言ってしまえば、ドメイン駆動設計 (DDD) がソフトウェア開発において最も重要視しているのは、ある問題に対する有用な model を提供する、ということです。つまり、その model さえ正しければ、それに基づいて設計されたソフトウェアは何らかの効果的な解決策を提示してくれるだろう、ということなのです。
仮に model が誤ったものだとしたら、それに基づいたソフトウェアが示すものは「回避」すべきものになってしまう可能性があります。
この本では domain model を構築するための基本を示すと同時に、その model が可能な限り外部の制約を受けず、よって、変更も機能追加等も容易になるようなアーキテクチャの構成も学んでいきます。
しかし、この本で紹介する以上に、DDD について、そして、domain model に関わるプロセス、ツール、テクニックについては知るべきことが多く存在します。この本でお伝えしているのはほんの「始まり」にすぎません。どうぞ「正しい」本を読んでより深い知識を得るようにしてください:
ビジネスにおいても同じことで、あるビジネス領域で使用されている「専門用語」というのは、domain model を凝縮したもの、つまりは、複雑なアイデアやプロセスを一言で言い表す為に作り出されてきたもの、ということです。
聞き慣れない単語、もしくは、ある単語の非日常的な使い方を耳にした場合、それが意味している domain model を理解し、それが導き出された「勝利の方程式・経験」をソフトウェアとして実現する必要があります。
この本を通して参照する domain model は、我々が実際に取り組んでいるビジネスにおいて成功を収めているオンライン家具ストア
MADE.com で採用しているものです。
このビジネスでは、世界中の生産者から家具を仕入れ、ヨーロッパのあらゆる国々へ向けて販売を行っています。
もしあなたがソファやコーヒーテーブルを購入した場合、その製品が生産国(ポーランド、中国、それともベトナムかもしれません)からあなたのお宅の居間にセットされるまでの最善な「流れ」を我々は見つけ出す必要があるのです。
よりシステマティックな話をすれば、製品の仕入れ (Purchasing)、販売 (Ecommerce)、発送 (Warehouse) を管理するための別々のシステムがあり、更に、お客さんの注文に応じてそれらのシステム間で情報をやり取りするためのシステム (Allocation) も存在します:
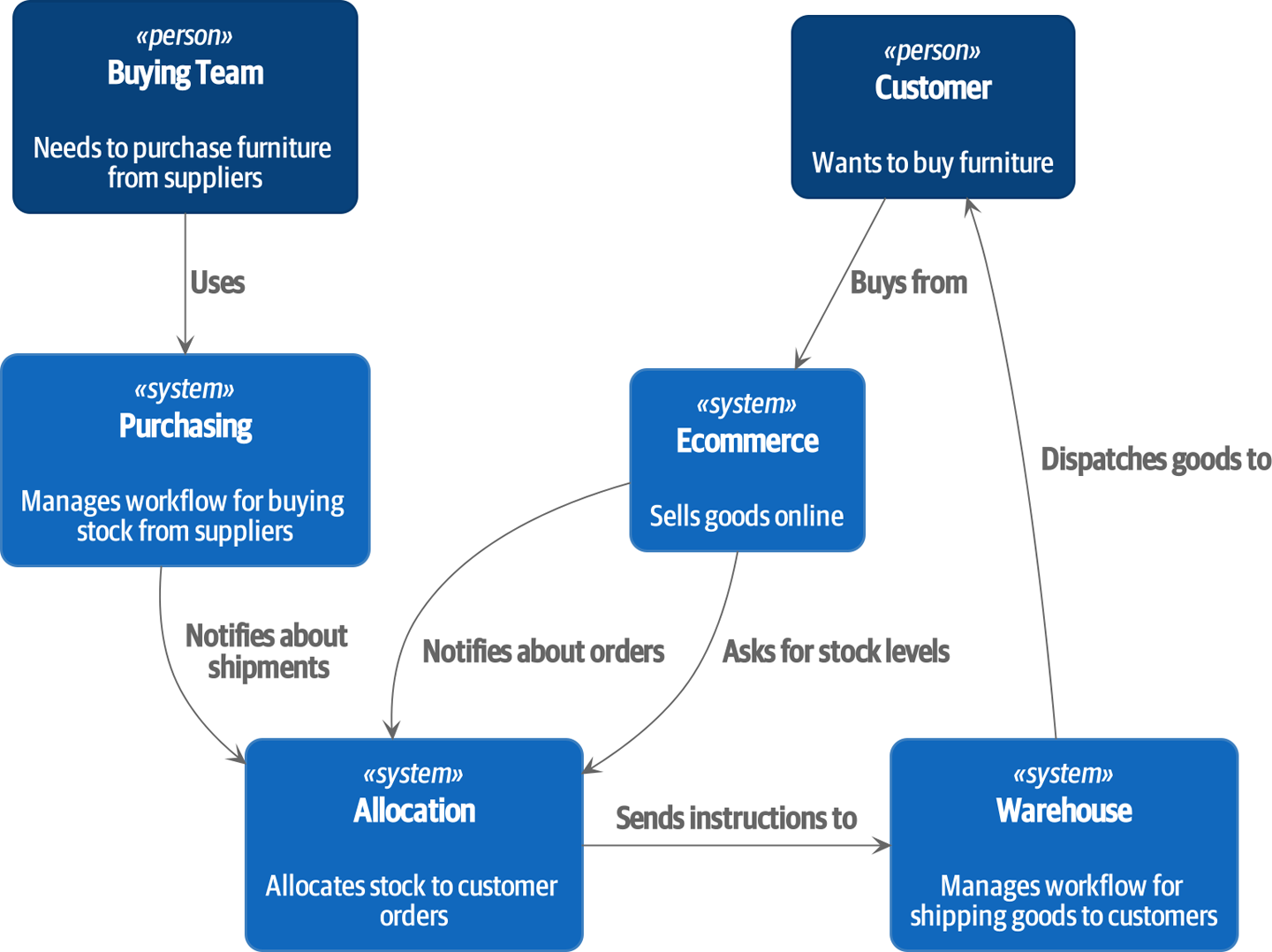
Figure 1-2. Context diagram for the allocation service
- Harry Percival, Bob Gregory (March 2020). Architecture Patterns with Python. O'Reilly Media, Inc -
さて、この本の内容をより興味深いものにするために、商品の動きをモニタする新たな allocation システムを構築したいと思います。
現在のところこのビジネスでは、在庫と配達までに要する時間を、倉庫に商品が存在するか、を基にオンラインストアで表示しています。
もし倉庫に在庫がない場合、その商品が改めて入荷するまで「在庫なし」と表示しているわけです。
さて、ここからが新たな allocation システムのアイデアです:
もし、全ての商品を製造段階から追跡可能なシステムがあれば、再入荷の日時も予測可能ですし、それらの商品を「在庫あり」として扱うこともできるようになります。
つまり、「配達するまでに要する時間」が若干長い「在庫商品」ということです。
これによって、オンラインストアで「在庫なし」と表示しなければならない商品はほとんどなくなり、さらには、国内倉庫の在庫品も最低限で済むことから、経費の節減にもつながることが期待できます。
しかし、allocation システムにはより複雑な処理が求められることになります。注文があるたびに倉庫の在庫を1つ減らせばよい、といった単純な操作では済みません。
今までとは異なる domain model が必要です。
Domain model を理解するには時間、忍耐と、気付いたことをすべて記録しておくためのノートが必要です。
まずは専門家と話し合いの場を持ち、最低限の要件を満たす domain model に必要な用語と規則について同意しておく必要があります。
この時、それぞれの規則への理解がより深まるように、可能な限り具体的な例を挙げてもらうことが必要でしょう。
そして、これらの規則を一言で言い表すことが可能な「専門用語/隠語 (DDD ではこれを ubiquitous language と称しています)」を取り決めることが重要です。
印象に残りやすい「専門用語」を創作することで、話し合いをスムーズに進めていくことが可能になります。
次の Some Notes on Allocation 備考欄には、domain 専門家との allocation についての討議中に書き留めておくべきノート内容の例を挙げてあります:
製品 (product) の管理単位は SKU。
SKU は Stock-Keeping Uint の略字であり "スキュー (skew)" と発音する。
顧客 (customers) は注文 (orders) をする。
1つ1つの注文は注文番号 (order reference) で区別され、それぞれの注文番号は複数の注文詳細 (order lines) から構成される。
1つ1つの注文内容は、SKU と 数量から成り立つ。
例えば:
10 units of RED-CHAIR (RED_CHAIR unit が 10)
1 unit of TASTELESS-LAMP (TASTELESS-LAMP unit が 1)
購買部門が手当てした製品は、有効在庫単位 (batch) として管理される。
batch にはそれぞれ固有の ID (batch 参照番号: reference) が割り当てられており、1つ1つの batch ID は SKU と数量 (quantity) に紐付けられている。
顧客からの注文があった時点で、注文内容を batch に反映 (allocate) する必要が生じる。
こうした反映を行うと同時に、その batch から「取り出した」注文品を顧客の住所宛てに発送することになる。
例えば、ある注文内容が「製品 A、数量 x」であれば、該当する製品 A の batch に注文内容を反映することで、有効在庫 (available quantity) が x 減少する、ということになる:
Batch: 20 SMALL-TABLE に対して 注文内容: 2 SMALL-TABLE を反映
Batch: 18 SMALL-TABLE に更新される
もし batch が注文内容よりも少なければ、その内容を反映 (allocate) することができない:
Batch: 1 BLUE-CUSHION に対して 注文内容: 2 BLUE-CUSHION
この注文内容を allocate してはいけない
また、同一注文番号内の同一注文内容を2回以上 allocate してはいけない:
Batch: 10 BLUE-VASE に対して 注文内容: 2 BLUE-VASE を反映
もしこの注文内容を再度 allocate してしまったとしても、batch は変わらず 8 BLUE-VASE でなければならない
ここまで挙げたような専門家との話し合いから model を作り上げていく例をお見せしたいと思います。
開発手法として TDD (Test-Driven Development: テスト駆動開発) を採用します。
まずは、是非ご自分でこの問題の解決策を考えてみてください。
手始めとして、話し合ったビジネスルールをしっかりと理解しているかを確認するために、いくつかのユニットテストを簡潔で分かり易いコードで記述してみましょう。
A first test for allocation (test_batches.py)
def test_allocating_to_a_batch_reduces_the_available_quantity():
batch = Batch('batch-001', 'SMALL-TABLE', qty = 20, eta = date.today())
line = OrderLine('order-ref', 'SMALL-TABLE', 2)
batch.allocate(line)
assert batch.available_quantity ==18
ユニットテスト名はこのテストで確認するべき「システムの動き」を表していて、クラス / 変数名は、この domain model における「専門用語 / 隠語: business jargon」から採っています。
私たち開発者は、このコードを開発の専門外である同僚にも目を通してもらう必要があるかもしれませんし、その場合であってもこのような名前付けを施しておくことで、システムの動きとして間違ってはいない、と賛同を得られるはずです。
続いて、これらの要求を満たすための domain model です:
First cut of a domain model for batches (models.py)
@dataclass(frozen=True)
class OrderLine:
orderid: str
sku: str
qty: int
class Batch:
def __init__(self, ref: str, sku: str, qty: int, eta: Optional[date]):
self.reference = ref
self.sku = sku
self.eta = eta
self.available_quantity = qty
def allocate(self, line: OrderLine):
self.available_quantity -= line.qty
この時点での実装は非常に簡単なものです: Batch クラスはただ単に int 値である available_quantity をラップし、allocation 時にその値を -1 しているだけです。
ある値を -1 するためだけにしては大袈裟なコードですが、この domain を正確にモデル化する過程でこの努力は報われるはずです。
Testing logic for what we can allocate (test_batches.py)
def make_batch_and_line(sku, batch_qty, line_qty):
return (
Batch("batch-001", sku, batch_qty, eta=date.today()),
OrderLine("order-123", sku, line_qty),
)
def test_can_allocate_if_available_greater_than_required():
large_batch, small_line = make_batch_and_line("ELEGANT-LAMP", 20, 2)
assert large_batch.can_allocate(small_line)
def test_cannot_allocate_if_available_smaller_than_required():
small_batch, large_line = make_batch_and_line("ELEGANT-LAMP", 2, 20)
assert small_batch.can_allocate(large_line) is False
def test_can_allocate_if_available_equal_to_required():
batch, line = make_batch_and_line("ELEGANT-LAMP", 2, 2)
assert batch.can_allocate(line)
def test_cannot_allocate_if_skus_do_not_match():
batch = Batch("batch-001", "UNCOMFORTABLE-CHAIR", 100, eta=None)
different_sku_line = OrderLine("order-123", "EXPENSIVE-TOASTER", 10)
assert batch.can_allocate(different_sku_line) is False
特別なことは何もありませんね。
同一の SKU に対して Batch と OrderLine オブジェクトを作成するコードを繰り返し繰り返し記述しなくてもいいように test suite を書き換えて、新たなメソッド can_allocate に対する単純な4つのテストを記述しました。
ユニットテスト名、変数名は先ほども述べたようにこの domain の専門家が使用している jargon から名付け、話し合いで得られたシステムの動きをコードに表したまでです。
このテストコードを元に、 Batch クラスに can_allocate() メソッドを実装します:
A new method in the model (model.py)
def can_allocate(self, line: OrderLine) -> bool:
return self.sku == line.sku and self.available_quantity >= line.qty
現在までのところ Batch.available_quantity の値を +1 / -1 するだけで事足りていますが、deallocate() メソッドを使用したテストをパスするための解決策はより複雑になってきます:
This test is going to require a smarter model (test_batches.py)
def test_can_only_deallocate_allocated_lines():
batch, unallocated_line = make_batch_and_line("DECORATIVE-TRINKET", 20, 2)
batch.deallocate(unallocated_line)
assert batch.available_quantity == 20
このテストでは、この OrderLine がすでに allocate されたものでない限り deallocate() は該当 batch に対して何ら影響を与えない、ということを確かめたいわけです。
そのためには、どの OrderLine がすでに allocate されているのか、ということを Batch クラスが把握している必要があります。
実装してみましょう:
The domain model now tracks allocations (model.py)
class Batch:
def __init__(self, ref: str, sku: str, qty: int, eta: Optional[date]):
self.reference = ref
self.sku = sku
self.eta = eta
self._purchased_quantity = qty
self._allocations: set[OrderLine] = set()
def allocate(self, line: OrderLine):
if self.can_allocate(line):
self._allocations.add(line)
def deallocate(self, line: OrderLine):
if line in self._allocations:
self._allocations.remove(line)
@property
def allocated_quantity(self) -> int:
return sum(line.qty for line in self._allocations)
@property
def available_quantity(self) -> int:
return self._purchased_quantity - self.allocated_quantity
def can_allocate(self, line: OrderLine) -> bool:
return self.sku == line.sku and self.available_quantity >= line.qty
Figure 1-3 はここまでの model を UML で表したものです:
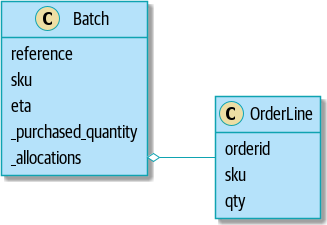
Figure 1-3. Our model in UML
- Harry Percival, Bob Gregory (March 2020). Architecture Patterns with Python. O'Reilly Media, Inc -
更新した Batch クラスでは allocate 済みの OrderLine オブジェクトを保持しています。
注文が来て、これを満たす有効在庫があれば、その OrderLine を allocate すると同時に set に追加します。
今回の実装では、available_quantity はただの int 値の保存変数ではなく、計算を伴うプロパティとして定義し直しました: 有効在庫数量 (purchased quantity) - 販売済み数量 (allocated quantity)
しかし対処しなければならない状況はまだまだありますね。
allocate() と deallocate() が共に条件を満たさずに「こっそり」終了したら ...、ん~、ちょっとドギマギします。
でも骨組みは整ってきています。
今回の実装でもう1つ触れておけば、_allocations を set 型としたことで、最後のテスト (test_can_only_deallocate_allocated_lines) の条件を簡単に満たすことができるようになっています。set に含まれる要素はユニーク (unique) ですから。
Last batch test! (test_batches.py)
def test_allocation_is_idempotent():
batch, line = make_batch_and_line("ANGULAR-DESK", 20, 2)
batch.allocate(line)
batch.allocate(line)
assert batch.available_quantity == 18
現在までのところでは「DDD を使うまでもないんじゃない?」「オブジェクト指向自体いらなくない?」といった批判は当然かもしれません、対象としている domain model 自体がかなり単純なものですから。
現実世界では、考慮に入れるべき規則や特殊ケースが頻出します:
例えば、顧客が配達日時の指定ができるようにする必要があるでしょう。
ということは、最も早く手当てできる batch に対する allocate だけでは対応できないかもしれません。
ある SKU が有効在庫として確保できていなくても、注文時点で直接製造元に問い合わせることで確保できるかもしれません。そうであれば、それに対応可能な新たなロジックが必要になります。
配送先住所によって、その地域を管轄する倉庫の batches に対してだけその注文を allocate できるようにする必要があるかもしれません。
しかしそうした場合でも、ある特定の SKU に関しては、その管轄倉庫に在庫がない場合に限り他地域の倉庫からの配送を可能にすることも必要かもしれません ...、などなど。
現実世界における実際のビジネスの現場では、この章で取り上げているよりもはるかに多くはるかに複雑な問題が、次から次へと矢継ぎ早に積み上がっていきます。
ただ、ここで取り上げている単純な domain model を土台として徐々に複雑な規則を盛り込んでいく予定ですし、最終的には現実世界における APIs、データベース、スプレッドシートで利用可能なものへと発展させていきます。
最初の思想に忠実に1つの domain model としてまとめ上げ、注意深くアプリケーション構造を積み上げていくことで「開発の泥沼」にはまることを避けることができるはずです。
もしあなたが type hints にぞっこんなら、primitive types にさえエイリアス名をつけて要素をより特定したいと思っていませんか?
そんなあなたに typing.NewType !!
Just taking it way to far, Taro-san! (ちょっとやり過ぎ?)
ここまで記述してきたコードの中では line という「言葉」を何気なく使用してきています。
しかし line とは何でしょう?
我々の domain model では、order (注文) は複数の line 要素から成り立っています。
そしてそれぞれの line は、SKU と数量 (quantity) から成り立っています。
order を YAML フォーマットでシンプルに表現してみると次のようになるでしょう:
Order_reference: 12345
Lines:
- sku: RED-CHAIR
qty: 25
- sku: BLU-CHAIR
qty: 25
- sku: GRN-CHAIR
qty: 25
お気付きのように、order には個別に認識するための reference がありますが、line にはそういったものはありません。
(もし、OrderLine クラスに order reference を含めたとしても、それは line 自体を個別に識別するものではありません)
あるビジネスモデルにおいて独自性のないデータを利用する場合、それを表現するために Value Object pattern を用いることがあります。
Value object は domain model に属するオブジェクトであり、それ自体が保持するデータによって個別に識別されるもので、通常 immutable なクラスとして実装されます:
OrderLine is a value object
@dataclass(frozen=True)
class OrderLine:
orderid: OrderReference
sku: ProductReference
qty: Quantity
dataclasses (もしくは namedtuples) の素晴らしい点は、「orderid, sku, qty が同一である2つの lines は等しい」という value equality の概念を与えてくれることです。
More examples of value objects
from dataclasses import dataclass
from typing import NamedTuple
from collections import namedtuple
@dataclass(frozen=True)
class Name:
first_name: str
surname: str
class Money(NamedTuple):
currency: str
value: int
Line = namedtuple('Line', ['sku', 'qty'])
def test_equality():
assert Money('gbp', 10) == Money('gbp', 10)
assert Name('Harry', 'Percival') != Name('Bob', 'Gregory')
assert Line('RED-CHAIR', 5) == Line('RED-CHAIR', 5)
ここで示した value objects は、これらはいかに機能すべきか、という現実世界における我々の感覚とマッチするものです。
'10ポンド紙幣' が話に上った時、我々は「どの」10ポンド紙幣なのか、という話をしているわけではありません。10ポンドの価値を表す紙幣全般、の話をしているわけです。
同様に、first name と last name の両方が一致すればそれらの名前は「同じ」ですし、注文番号、製品コード、数量が一致していればそれらの lines は等しいのです。
さらに、value object にはより複雑な「動き (behavior)」を付け加えることも可能です。
一般的には、数値計算といった操作をサポートするのが普通です。
fiver = Money('gbp', 5)
tenner = Money('gbp', 10)
def can_add_money_values_for_the_same_currency():
assert fiver + fiver == tenner
def can_subtract_money_values():
assert tenner - fiver == fiver
def adding_different_currencies_fails():
with pytest.raises(ValueError):
Money('usd', 10) + Money('gbp', 10)
def can_multiply_money_by_a_number():
assert fiver * 5 == Money('gbp', 25)
def multiplying_two_money_values_is_an_error():
with pytest.raises(TypeError):
tenner * fiver
1つの order line は、order ID, SKU, quantity によって他のものと識別されます。
もしそれらの値のいずれかを変えるとすると、それはその order line の変更、ではなく、新しい order line の作成、になります。
Value object である、ということはつまりこういうことなのです。
それ自体が保持するデータそのものによって識別され、変化を受け入れながら長期間利用されるものではありません。
では batch とは何なのでしょう?それは reference によって識別されます。
値や状態を変化させつつ長期的に特性 (ID) を保持し続ける domain object のことを我々は entity (エンティティ) という言葉で表します。
前出の例で我々は Name クラスを value object として定義しました。
もし 'Harry Percival' という値を保持する Name オブジェクトがあった場合、その一文字を変えて 'Barry Percival' としたら、それは新しい Name オブジェクトを作成した、ということです。
'Harry Percival' と 'Barry Percival' が同一でないことは明らかですね。
名前 というオブジェクトそのものは変更できません...
def test_name_equality():
assert Name('Harry', 'Percival') != Name('Barry', 'Percival')
しかし Harry という人物 (person) に関してはどうでしょう?
「人間」の名前、婚姻歴、時には性別も変化しますが、しかしそれでも「同一の個人」です。
これが「長期的に ID を保持し続ける」ということであって、名前オブジェクト (value object) と人間オブジェクト (entity) の違いです:
でも 人間 オブジェクトの値 / 状態は変更可能です!
class Person:
def __init__(self, name: Name):
self.name = name
def test_barry_is_harry():
harry = Person(Name('Harry', 'Percival'))
barry = harry
barry.name = Name('Barry', 'Percival')
assert harry is barry and barry is harry
エンティティ (entities) は値 (values) とは異なり自己 ID について同一性を保持し続けます (identity equality)。
あるエンティティの属性値を変更したとしても、変更後のエンティティは変更前のエンティティと同一のものです。
我々の例において batches はエンティティです。
line を allocate することも、到着予定日を変更することも可能ですが、それは変わらず同じ batch です。
あるクラスがエンティティであることをコードで表現する場合、通常 equality operator (__eq__) を明示的に実装します:
Implementing equality operators (model.py)
class Batch:
...
def __eq__(self, other):
if not isinstance(other, Batch):
return false
return other.reference == self.reference
def __hash__(self):
return hash(self.reference)
Python の __eq__ magic method (special method / dunder method) は、クラスインスタンスに対して == オペレータが適用された場合の振る舞いを記述するものです。
Entity オブジェクト、value オブジェクトの設計時に、__hash__ の扱いを考慮することは重要です。
Python では、ハッシュ可能なオブジェクト (__hash__() を実装しているオブジェクト) は set の要素、ならびに、dict の key として使用可能である、といったように、そのオブジェクトの振る舞いを決定する要因となるためです。
詳しくは
python の公式ドキュメント を参照してください。
Value オブジェクトの場合、ハッシュは全ての属性値を考慮したものであるべきであり、そのオブジェクトが immutable であることを保証すべきです。
あるクラスが immutable であることを保証するために、frozen 属性に True を設定した @dataclass() デコレータでそのクラスを修飾する手法を利用できます。
Entity オブジェクトの場合の選択肢の一つは、hash として None を設定することです。
これはつまり、このオブジェクトはハッシュ可能ではない、すなわち、set の要素とはなり得ない、といったことを宣言することになります。
一方で、このエンティティオブジェクトをどうしても set や dict 操作の対象として利用したい、といった場合は、hash を算出する元となる属性として、Batch クラスにおける reference のような、そのエンティティに特有の値を定義しているものを利用しなければなりません。
また、その属性値が読み取り専用 (read-only) となるような実装を心掛けるべきでしょう。
これは非常にトリッキーな分野です。独自の __hash__ を実装するのであれば同時に __eq__ も実装すべきです。
どうすればよいか迷う、より深く理解したい、という方は Hynek Schlawack の
こちら の記事を参考にしてください。
Sometimes, it just isn't a thing.
- Eric Evans, Domain-Driven Design
Evans は、entity や value object の枠には収まらない Domain Service 操作についても触れています。batch に対して order line を割り当てる、というのはどうも「機能 / 作用」と捉える方が自然なようですし、Python はマルチパラダイム言語 (multiparadigm language: 手続き型、関数型、オブジェクト指向型、といったスタイルを組み合わせている言語) ですから、この操作を関数として表現することも可能です。
そのような関数を対象として TDD (テスト駆動開発) を行ってみましょう:
Testing our domain service (test_allocate.py)
def test_prefers_current_stock_batches_to_shipments():
in_stock_batch = Batch('in-stock-batch', 'RETRO-CLOCK', 100, eta=None)
shipment_batch = Batch('shipment-batch', 'RETRO-CLOCK', 100, eta=tomorrow)
line = OrderLine('oref', 'RETRO-CLOCK', 10)
allocate(line, [in_stock_batch, shipment_batch])
assert in_stock_batch.available_quantity == 90
assert shipment_batch.available_quantity == 100
def test_prefers_earlier_batches():
earliest = Batch('speedy-batch', 'MINIMALIST-SPOON', 100, eta=today)
medium = Batch('normal-batch', 'MINIMALIST-SPOON', 100, eta=tomorrow)
latest = Batch('slow-batch', 'NIMIMALIST-SPOON', 100, eta=later)
line = OrderLine('order1', 'MINIMALIST-SPOON', 10)
allocate(line, [medium, earliest, latest])
assert earliest.available_quantity == 90
assert medium.available_quantity == 100
assert latest.available_quantity == 100
def test_returns_allocated_batch_ref():
in_stock_batch = Batch('in-stock-batch-ref', 'HIGHBROW-POSTER', 100, eta=None)
shipment_batch = Batch('shipment-batch-ref', 'HIGHBROW-POSTER', 100, eta=tomorrow)
line = OrderLine('oref', 'HIGHBROW-POSTER', 10)
allocation = allocate(line, [in_stock_batch, shipment_batch])
assert allocation == in_stock_batch.reference
そして allocate サービスはこのようになるでしょう:
A standalone function for our domain service (model.py)
def allocate(line: OrderLine, batches: List[Batch]) -> str:
batch = next(
b for b in sorted(batches) if b.can_allocate(line)
)
batch.allocate(line)
return batch.reference
allocate() の実装における next() の利用では賛否が分かれるかもしれませんが、Batch オブジェクトのリストに対する sorted() の適用に関しては大いに賛同していただけると思います、これは python における構文としては「当たり前」なもの (idiomatic Python: python におけるコードの慣用的な記述方法) ですから。
ただし sorted() が機能するためには、該当する domain model (Batch class) に __gt__() ダンダーメソッドを実装する必要があります:
Magic method can express domain semantics (model.py)
class Batch:
...
def __gt__(self, other):
if self.eta is None:
return False
if other.eta is None:
return True
return self.eta > other.eta
domain model 設計時において考慮すべき最後のコンセプトは「例外」です。我々の domain においても、在庫がない場合には注文を allocate できない、という規則を、専門家との話し合いで指摘されています。システムではその状態を domain exception (ドメイン例外) によって取得します:
Testing out-of-stock exception (test_allocate.py)
def test_raises_out_of_stock_exception_if_cannot_allocate():
batch = Batch('batch1', 'SMALL-FORK', 10, eta=today)
allocate(OrderLine('order1', 'SMALL-FORK', 10), [batch])
with pytest.raises(OutOfStock, match='SMALL-FORK'):
allocate(OrderLine('order2', 'SMALL-FORK', 1), [batch])
実装に関することであまり退屈させたくはないのですが、定義するカスタム例外クラスの名前についても、エンティティや value objects、サービスなどと同じように ubiquitous language に則るべきです:
Raising a domain exception (model.py)
class OutOfStock(Exception):
pass
def allocate(line: OrderLine, batches: List[Batch]) -> str:
try:
batch = next(
...
)
except StopIteration:
raise OutOfStock(f'SKU [{line.sku}] - 在庫切れ')
この章でカバーした内容を図示すると以下のようになります:
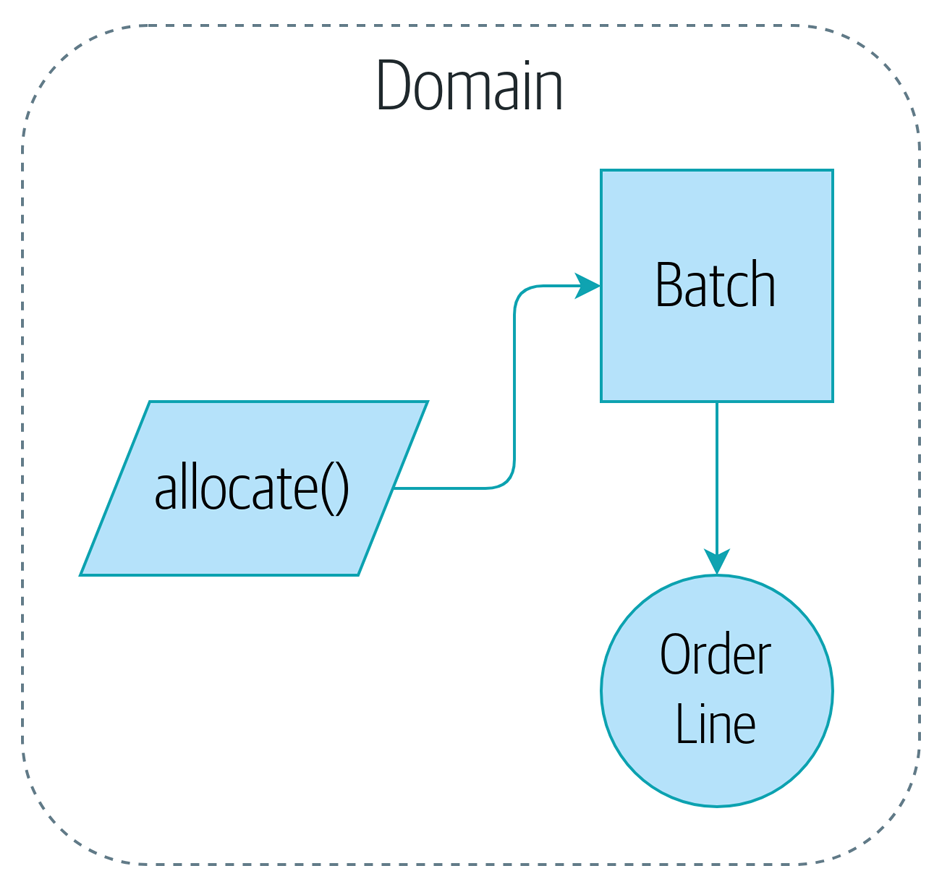
Figure 1-4. Our domain model at the end of the chapter
- Harry Percival, Bob Gregory (March 2020). Architecture Patterns with Python. O'Reilly Media, Inc -
サービスも記述しましたし、まあまあの出来栄えです。ただ、データベースが必要ですね...

