ビジネスの現場における規則 (ビジネスルール: core logic) と該当業務に必要なデータ (infrastructural concerns) を切り離して実装/管理すべく、「依存性逆転の原則 (dependency inversion principle)」に則って開発をしていきましょう。
ここでは Repository pattern (リポジトリパターン) を紹介します。データストレージ (data storage) を抽象化することで、モデルレイヤー (model layer) とデータレイヤー (data layer) を切り離すことができるようになります。
この章では、こうした抽象化によりデータベース処理の煩雑さが隠蔽され、いかにシステムのテストが容易になるか、ということの具体的な例を示します。
Figure 2-1 は、これから目指す実装形態を簡単に図示したものです。ご覧のように、domain model とデータベースの間にリポジトリオブジェクトを設置します:
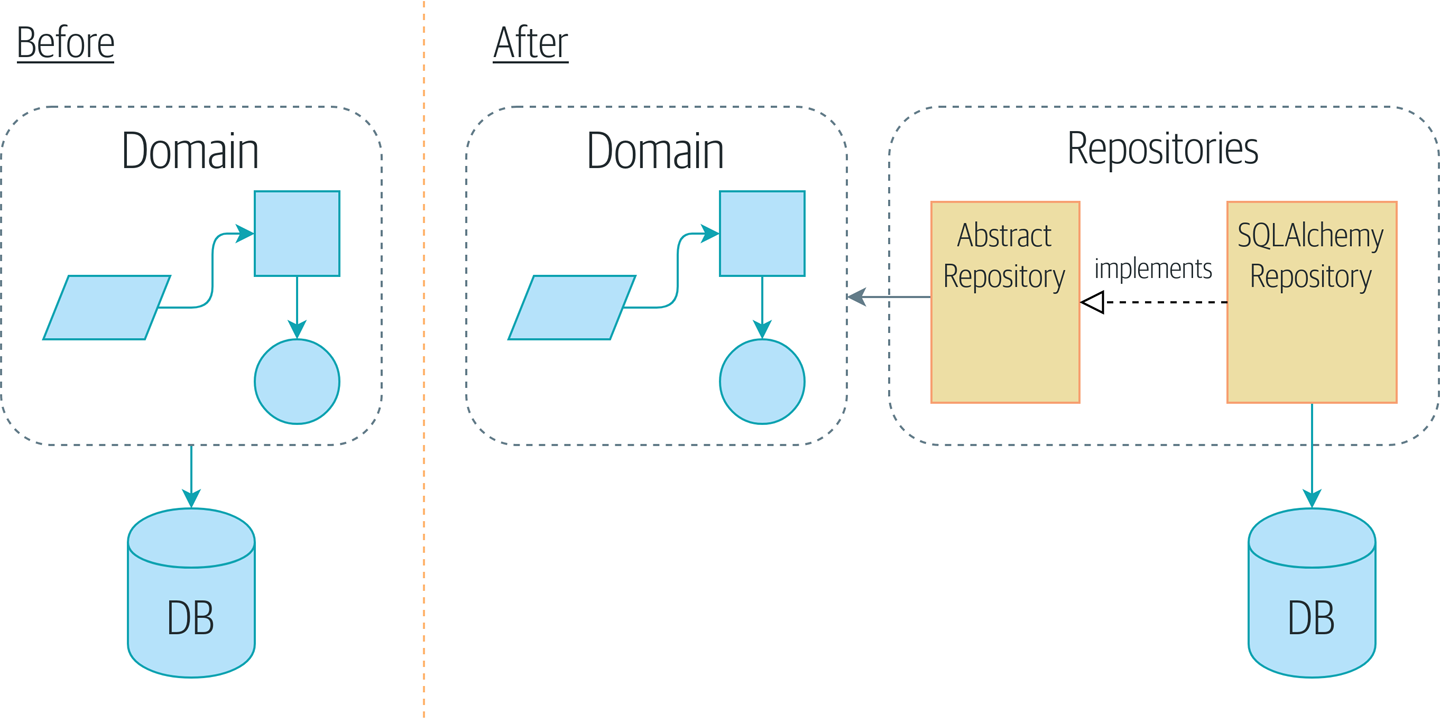
Figure 2-1. Before and after the Repository pattern
- Harry Percival, Bob Gregory (March 2020). Architecture Patterns with Python. O'Reilly Media, Inc -
第1章では、order を有効在庫の batch に allocate する単純な domain model を記述しました。この段階ではデータへの依存関係は何もありませんでしたから、テストを記述する際に何らかのセットアップが必要になることもなく非常に簡単に作成することが可能でした。
しかし、データベースや API を通してデータの取得を行うようになった場合、テストデータの作成、テスト自体の記述や維持は途端に難しくなります。
さらに、開発段階では「完璧」に動作するこうした model も、ユーザーの手に委ねられると同時にスプレッドシート / ウェブブラウザ上におけるデータ閲覧/操作、データ自体の競合 (race condition) といった現実問題に直面することになります。
これから数章に渡って、こうした「完璧」な domain model をいかにして「外部の現実」に合わせ込んでいったらいいのか、を見ていくことにしましょう。
本来開発には迅速さが求められます。つまり、条件を満たした最小構成の製品をいかに速く提供できるか、が優先事項なわけです。我々のプロジェクトで言えばそれは、web API の提供、ということになるでしょう。現実の開発では、いきなりエンドツーエンド (end-to-end) のテストに取り掛かり、web フレームワークに組み入れ、実環境でのテストを繰り返す、ということもあるかもしれません。
しかし手段、手順はどうであれ、何らかの形でデータを保管しておく必要があります。そしてこれはあくまでも「テキストブック」ですから、少し時間がかかったとしても、ストレージとデータベースについて考えることから始めたいと思います。
最初の API エンドポイントを作成するとしたら次のようなものになるでしょう:
What our first API endpoint will look like
@flask.route.gubbins
def allocate_endpoint():
line = OrderLine(request.params, ...)
batches = ...
allocate(line, batches)
return 201
軽量であるためここでは Flask を利用しますが、この本を読み進むために Flask の知識が必要である、ということではありません。実際、フレームワークに何を利用するか、はあまり重要なことではないことが読み進むうちに明白になってくると思います。
やるべきことは、データベースから batch 情報を取り出し、それを基に domain model オブジェクトを作成し、それをデータベースに保存する機能を実装することです。
UI (ユーザーインターフェース)、ロジック、データベースから成るシステムは一般的に layered architecture (階層アーキテクチャ) として構築されます:
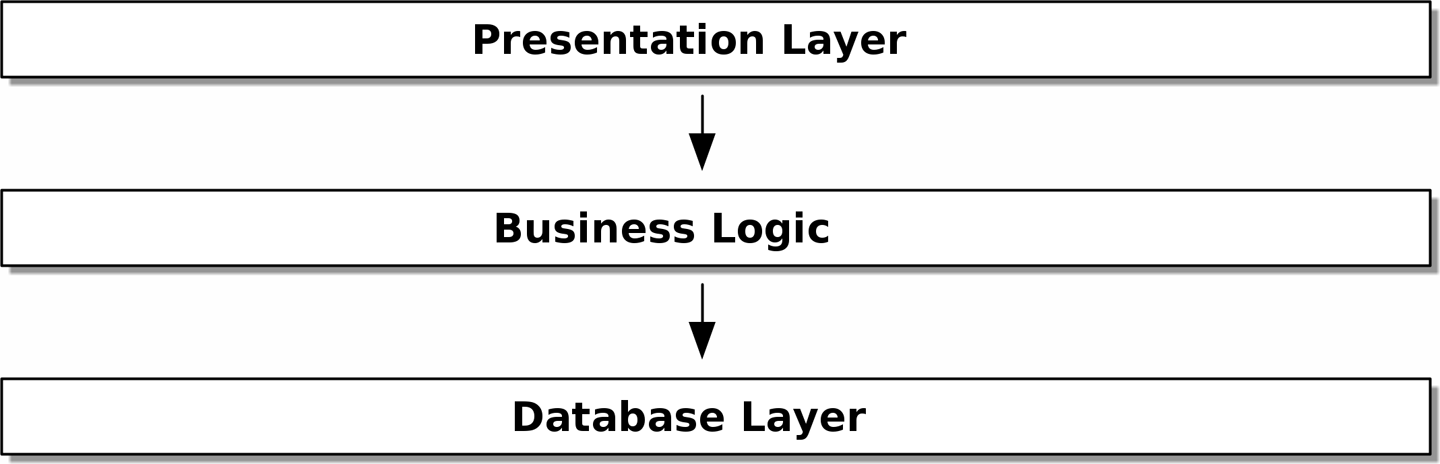
Figure 2-2. Layered architecture
- Harry Percival, Bob Gregory (March 2020). Architecture Patterns with Python. O'Reilly Media, Inc -
Model-View-Controller (MVC) も、Django における同等のアーキテクチャである Model-View-Template も、結局のところその狙いは「役割における層の分離」ですし (それはいいことですよね)、ある層は自分の下の階層にだけ依存する、というものです。
しかし我々の domain model には依存関係といったものを一切持たせたくないのです (ここで言っている「依存関係」というのは「stateful な依存関係」という意味です。ヘルパーライブラリに「頼る」のは構いません。ただ、ORM (Object-Relational Mapping) や web framework といったものは「ダメ」ということです)。Figure 2-2 でいうところの Presentation Layer や Database Layer に属すべき問題が domain model まで深く影響を及ぼして、ユニットテストの効率が落ちたり、domain model 自体の変更が困難になるような事態を避けたいのです。
ですから、domain model が「内側」に位置し、依存関係はそれに向かって「外から内へ」流れ込む、というアーキテクチャにしたいのです; このような構造を onion architecture (オニオン構造: 玉ねぎの「年輪」のように輪が重なりその中心に domain model が位置します) と呼ぶ人もいます:
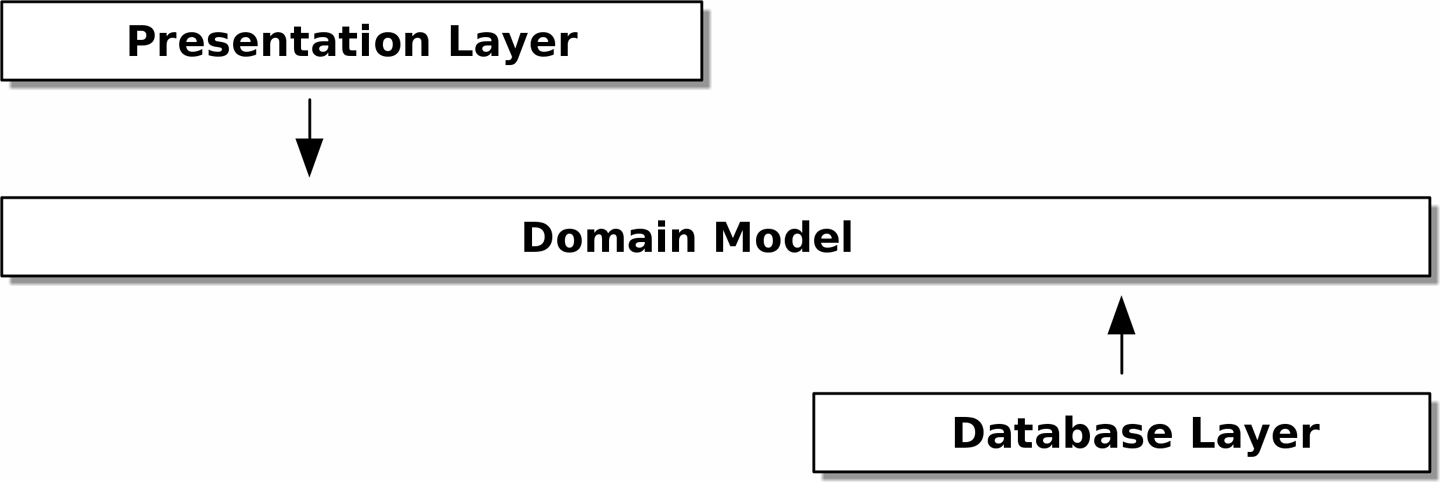
Figure 2-3. Onion architecture
- Harry Percival, Bob Gregory (March 2020). Architecture Patterns with Python. O'Reilly Media, Inc -
アーキテクチャパターン (architectural patterns) について学んだことがある方の中には、次のような疑問を感じた方もいるかもしれません:
これって ports and adapters なの? それとも hexagonal arcitecture なの? onion architecture とは違うの? clean architecture って何? 何が port で、何が adapter なの? 同じようなことを言ってるみたいだけど、何でこんなに単語がいっぱいあるの?
これらの違いを議論するのが好きな方もいるでしょうが、これらの「単語」が言わんとしている内容はほぼ同じです; 依存性逆転の原則 (dependency inversion principle) です。つまり、上位モジュール (hige-level modules: domain model に当たります) は下位モジュール (low-level modules: データベースアクセスやユーザーインターフェースを受け持つ基盤モジュール) に依存すべきではない、ということです
(このことに関する
Mark Seemann のブログ は秀逸です)。
この本でも、「抽象への依存」について若干「重箱の隅をつつく」的な話や、Pythonic なインターフェースの実装手段とは、といった話題を取り上げます。
ここで我々の domain model を確認しておきましょう; Batch に対して OrderLine を適用する/保存する行為を allocate と言っていました。そして allocate した結果を Batch オブジェクトで set の要素として保持しているわけです:
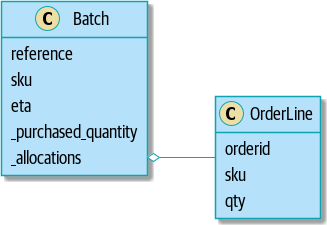
Figure 2-4. Our Model
- Harry Percival, Bob Gregory (March 2020). Architecture Patterns with Python. O'Reilly Media, Inc -
では、これをリレーショナルデータベース (relational database) として表現してみましょう。
昨今の開発現場において、「生の」SQL を開発者自身が記述する、ということはほぼないと思います。ある種のフレームワークを利用し、定義したモデルを基に SQL を「吐き出させる」のが一般的でしょう。
こうしたフレームワークのことを ORMs (Object-Relational Mappers) と呼んでいます。domain model とそれを基とするオブジェクト群、データベースとそこで表現されるリレーション、を関連付ける (橋渡しする) 役割を担っているからです。
ORM により実現される最も重要な事項は「永続性の無視 (pesistence ignorance)」です; つまり、domain model の作成時に、データがどのように読み込まれ、また、保存されるかを一切気にする必要がない、ということです。このことにより、ある特定のデータベース機能に直接依存する必要がない「クリーン」な実装をすることが可能になります (この意味では ORM の採用はすでに DIP の例である、とも言えます。ハードコードした SQL の代わりに ORM により提供される抽象に依存するわけです。ただし、これだけでは我々の条件は満たされませんし、この本は ORM についてのものでもありません)。
もしあなたが典型的な SQLAlchemy のチュートリアルに目を通したことがあるのなら、以下のようなコードを目にしたことがあるでしょう:
SQLAlchemy "declarative" syntax, model depends on ORM (orm.py)
from sqlalchemy import Column, ForeignKey, Integer, String
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy.orm import relationship
Base = declarative_base()
class Order(Base):
id = Column(Integer, primary_key=True)
class OrderLine(Base):
id = Column(Integer, primary_key=True)
sku = Column(String(250))
qty = Integer(String(250))
order_id = Column(Integer, ForeignKey('order.id'))
order = relationship(Order)
class Allocation(Base):
...
SQLAlchemy に通じていないとしても、model の構成要素すべてが ORM にベッタリと依存し、非常に「醜い」コードになってしまっているのは理解できるのではないでしょうか?この実装を見て「この model はデータベースからは隔離されている」と言えるでしょうか? model の1つ1つの属性がデータベースのフィールド1つ1つにマッピングされているこの状況で、どうやって model とストレージを切り離して考えることができるのでしょうか?
Django の方により馴染みが深いのであれば、上に挙げた SQLAlchemy の domain model 定義コードは次のようになるでしょう:
同じことですね - model クラスは ORM クラスを継承しています、つまり ORM に依存している、ということです。この依存関係の向きを逆にしたいわけです。
Django では SQLAlchemy における Classical Mapping に相当する機能は提供されていませんが、Appendix では Django において「依存性逆転の原則」と「リポジトリパターン」を適用する方法の例をお見せします (🙇現時点では当方の勉強がそこまで到達していません。可能になったらリンクを張ります🙇)。
SQLAlchemy は、スキーマを別に定義し、スキーマと domain model を相互変換するためのマッパー (mapper) も明示的に定義する、という手法も提供してくれています。これを SQLAlchemy では classical mapping と呼んでいます:
Explicit ORM mapping with SQLAlchemy Table objects (orm.py)
(SQLAlchemy を利用した明示的な ORM マッピング)
from sqlalchemy.orm import mapper, relationship
import model
metadata = MetaData()
order_lines = Table(
'order_lines', metadata,
Column('id', Integer, primary_key=True, autoincrement=True),
Column('sku', String(255)),
Column('qty', Integer, nullable=False),
Column('orderid', String(255)),
)
...
def start_mappers():
lines_mapper = mapper(model.OrderLine, order_lines)
この実装後 start_mappers() 関数を呼び出すことで、データベースに対して domain model インスタンスの読み込み、保存が簡単に行えるようになります。しかも、この関数を呼び出さない限り、domain model の各クラスとデータベースの紐付けは行われないのです。
これによって、Alembic を利用してマイグレーションを実行したり、後で実際に試しますが、ドメインクラスを通してクエリを発行したり、といった SQLAlchemy の利点をすべて享受可能になります。
このように自分で ORM を設定しようとする際には、以下のようなテストを記述すると助けになるかもしれません:
Testing the ORM directly (throwaway tests) (test_orm.py)
def test_orderline_mapper_can_load_lines(session):
session.execute(
'INSERT INTO order_lines (orderid, sku, qty) VALUES '
'("order1", "RED-CHAIR", 12),'
'("order1", "RED-TABLE", 13),'
'("order2", "BLUE-LIPSTICK", 14)'
)
expected = [
model.OrderLine("order1", "RED-CHAIR", 12),
model.OrderLine("order1", "RED-TABLE", 13),
model.OrderLine("order2", "BLUE-LIPSTICK", 14),
]
assert session.query(model.OrderLine).all() == expected
def test_orderline_mapper_can_save_lines(session):
new_line = model.OrderLine("order1", "DECORATIVE-WIDGET", 12)
session.add(new_line)
session.commit()
rows = list(session.execute('SELECT orderid, sku, qty FROM "order_lines"'))
assert rows == [('order1', 'DECORATIVE-WIDGET', 12)]
これらのテストは一度限りのものとなるでしょうが、やっていけばすぐに分かるように、ORM と domain model の依存性を一旦逆転させてしまえば、リポジトリパターン (Repository pattern) と言われている抽象化手段を実装するのはそれほど手間のかかるものではありません。そして、リポジトリパターンを実装することで、テストの記述が容易になるだけではなく、様々な種類のテストを記述するための簡易なインターフェースを提供してくれることにもなります。
しかし我々の当初の目的であった「従来の依存関係の逆転」はすでに達成されています: domain model はデータベースアクセス等の基盤機能からは独立しています。もし SQLAlchemy ではなく他の ORM、全く異なるストレージシステムなどを採用したとしても domain model に何ら変更を加える必要はありません。
Domain model で実装すべき機能によっては、とくにそれがオブジェクト指向の枠組みに収まりきらない場合は特に、その機能を ORM によって正確に実装する困難さが増し、ついには、domain model 自体を変更する必要が生じることがあるかもしれません。そのような必要性があまりにも頻繁に生じるようであればトレードオフを考慮する必要があるでしょう。"Practicality beats purity! (実用性は[理論的]完全性に勝る)" と Zen of Python にも書かれています。
ただし、現時点での我々の API エンドポイントは次のようで、十分に機能します:
Using SQLAlchemy directly in our API endpoint
@flask.route.gubbins
def allocate_endpoint():
session = start_session()
line = OrderLine(
request.json['orderid'],
request.json['sku'],
request.json['qty'],
)
batches = session.query(Batch).all()
allocate(line, batches)
session.commit()
return 201
Repository pattern (リポジトリパターン) は persistent storage (永続/持続ストレージ) を抽象化するもので、全てのデータがメモリ上に展開されているように振舞います。
使用可能なメモリ領域に制限がないのであれば、わざわざデータベースのことを考慮する必要はありません。好きな時にオブジェクトを利用するだけです。これってどんな感じなんでしょう?
You have to get your data from somewhere
(データは「どっか」から引っ張ってこなきゃ...)
import all_my_data
def create_a_batch():
batch = Batch(...)
all_my_data.batches.add(batch)
def modify_a_batch(batch_id, new_quantity):
batch = all_my_data.batches.get(batch_id)
batch.change_initial_quantity(new_quantity)
オブジェクトはメモリ上に存在するとしても、再度利用できるように「どこか」に保存しておくことは必要です。メモリ上のデータに対しては、list や set に対するように新しいオブジェクトを追加することができます。しかもわざわざ .save() を呼び出して明示的に保存する必要もありません。オブジェクトの取得、変更はすべてメモリ上で実行することが可能です。
最も簡素なリポジトリは2つのメソッドを提供するだけです: リポジトリに新しい要素を追加する add() と、リポジトリ内の要素を1つ返す get() です。私たちが作成する domain とサービスレイヤ (service layer) には、この2つのメソッドだけを使用する制約を課したいと思います。敢えてそうすることが、domain model がデータベースへ依存しないようにする最も簡単な方法だからです。
我々のリポジトリの抽象基底クラス (ABC: Abstract Base Class) は次のようになるでしょう:
The simplest possible repository (repository.py)
class AbstractRepository(abc.ABC):
@abc.abstractmethod
def add(self, batch: model.Batch):
raise NotImplementedError
@abc.abstractmethod
def get(self, reference) -> model.Batch:
raise NotImplementedError
この例のように抽象基底クラスを利用したのには示唆的な意味合いも込めています: つまり、リポジトリを抽象化したインターフェースとは何たるか、の説明の助けになれば、ということです。
現実的には、製品コードからの ABCs の割愛はよく行われています。それは、Python においては ABCs を考慮せずに済んでしまうことが多く、またそれらがメンテナンス対象から外れ、最悪の場合は誤った使い方がされてしまう可能性もあるためです。実際のところ Python において抽象化を実現する場合、duck typing (ダックタイピング) だけに依拠してしまうことは多々発生しています。Pythonista (Python 愛好者) にとって add(thing) メソッドと get(id) メソッドが実装されているオブジェクトはすべてリポジトリなのです。
ここで用いた ABCs の代替として考えられるものとして protocols (PEP 544) があります。protocols を利用すれば継承することなく型チェックを行うことが可能なため、"composition over inheritance (継承 [is-a] よりも 包含 [has-a] を重視)" 派の方には特に好まれるようです。
You know they say economists know the price of everything and the value of nothing? Well, programmers know the benefits of everything and the trade-offs of nothing.
この本では、あるアーキテクチャパターンを紹介する際には必ず、それが何をもたらしどのような犠牲を伴うのか、ということも考えていきます。
まずは少なくとも、抽象化のための追加の階層が必要になります。それは、複雑さの軽減に役立つことを結果的に期待してのものではありますが、部分的には煩雑さが増し、可動部分とメンテナンスの箇所が増大するという負の面も伴います。
我々はすでに DDD を採用し「依存性逆転の原則」に取り組んできていますから、この段階で最も簡単な選択肢の1つはリポジトリパターンでしょう。コード実装に関する限りでいえば、SQLAlchemy による抽象化 (session.query(Batch)) 部分を自らデザインした batches_repo.get に置き換えるだけですから。
データ操作の対象となる domain オブジェクトを新規に追加するたびに、新たなリポジトリクラスを実装するための数行のコードを記述する必要はありますが、それによってストレージ層を抽象化し、私たち自身がそれをコントロールすることができるのです。リポジトリパターンを導入することで、保存方法を根本的に変更することが容易に可能になるばかりか、これから見ていくように、単体テスト (unit tests) の手間を大幅に軽減することも可能です。
それらに加え、ドメイン駆動設計 (DDD) においてリポジトリパターンの知名度は抜群ですから、もし Java や C# などから Python の開発環境に来たプログラマと一緒のチームになったとしてもまず問題はないはずです。
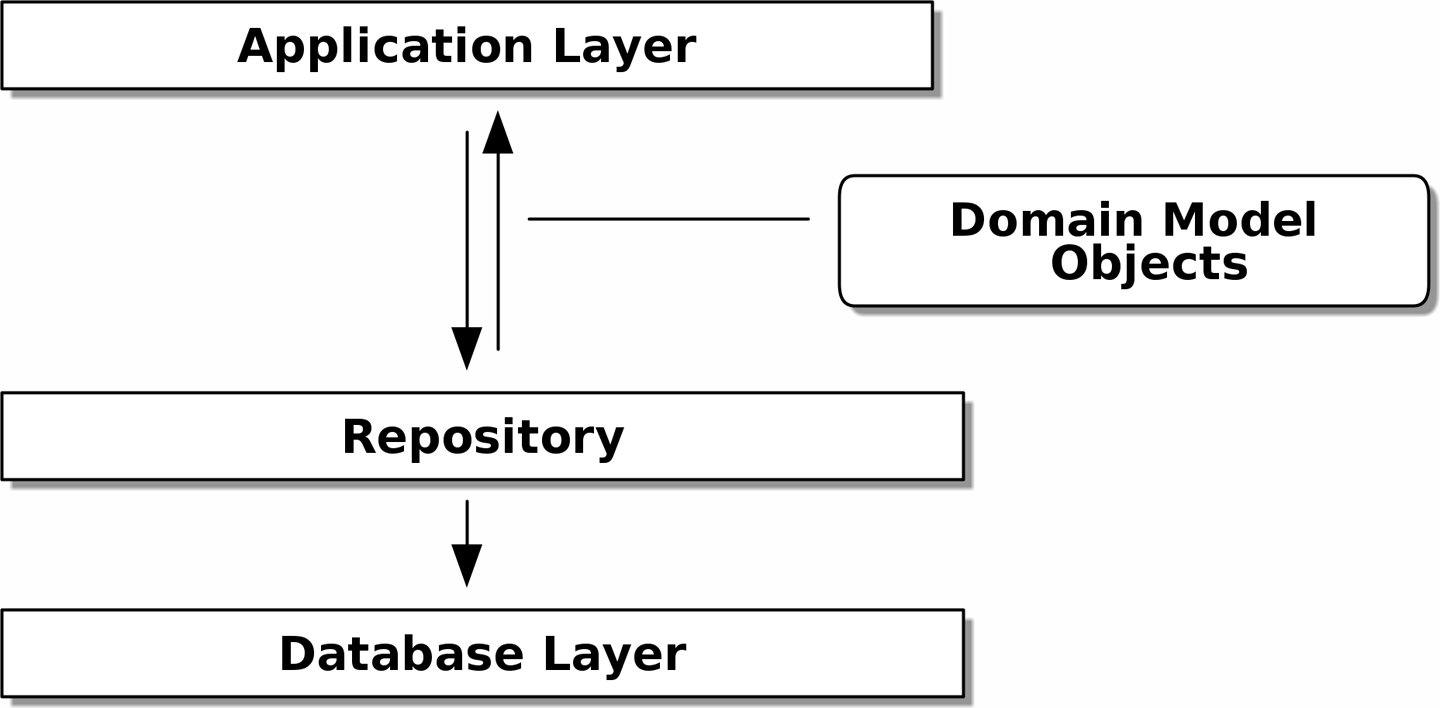
Figure 2-5. Repository pattern
- Harry Percival, Bob Gregory (March 2020). Architecture Patterns with Python. O'Reilly Media, Inc -
今までと同じようにテストを記述することから始めましょう。今回のテストは、リポジトリ実装部分がデータベースと期待通りにやり取り可能か、を調べることになりますから、「統合/結合 テスト (integration test) 」に分類できるでしょう: 「生」の SQL 文とリポジトリ実装コードへの呼び出し、そして assertions が混在することになります。
これまでの ORM 関連のテストとは異なり、これから記述するテストの基盤部分は長期にわたって保持しておくべき候補となり得るものです。特に、domain model のいずれかのパートが object relational map と関連が深い場合には尚更です。
Repository test for saving an object (test_repository.py)
def test_repository_can_save_a_batch(session):
batch = model.Batch('batch1', 'RUSTY-SOAPDISH', 100, eta=None)
repo = repository.SqlAlchemyRepository(session)
repo.add(batch)
session.commit()
rows = list(session.execute(
'SELECT reference, sku, _purchased_quantity, eta FROM "batches"'
))
assert rows == [('batch1', 'RUSTY-SOAPDISH', 100, None)]
次のテストは batches の取得と allocate を含むためより複雑になります:
Repository test for retrieving a complex object (test_repository.py)
def insert_order_line(session):
session.execute(
'INSERT INTO order_lines (orderid, sku, qty)'
' VALUES ("order1", "GENERIC-SOFA", 12)'
)
[[orderline_id]] = session.execute(
'SELECT id FROM order_lines WHERE orderid=:orderid AND sku=:sku',
dict(orderid='order1', sku='GENERIC-SOFA')
)
return orderline_id
def insert_batch(session, batch_id):
...
def test_repository_can_retrieve_a_batch_with_allocations(session):
orderline_id = insert_order_line(session)
batch1_id = insert_batch(session, 'batch1')
insert_batch(session, 'batch2')
insert_allocation(session, orderline_id, batch1_id)
repo = repository.SqlAlchemyRepository(session)
retrieved = repo.get('batch1')
expected = model.Batch('batch1', 'GENERIC-SOFA', 100, eta=None)
assert retrieved == expected
assert retrieved.sku == expected.sku
assert retrieved._purchased_quantity == expected._purchased_quantity
assert retrieved._allocations == {
model.OrderLine('order1', 'GENERIC-SOFA', 12)
}
これらのテストを満たすリポジトリは次のようなものになるはずです:
A typical repository (repository.py)
class SqlAlchemyRepository(AbstractRepository):
def __init__(self, session):
self.session = session
def add(self, batch):
self.session.add(batch)
def get(self, reference):
return self.session.query(model.Batch).filter_by(reference=reference).one()
def list(self):
return self.session.query(model.Batch).all()
Flask を利用した API エンドポイントは次のような実装になるでしょう:
Using our repository directly in our API endpoint
@flask.route.gubbins
def allocate_endpoint():
batches = SqlAlchemyRepository.list()
lines = [
OrderLine(l['orderid'], l['sku'], l['qty']) for l in request.params...
]
allocate(lines, batches)
session.commit()
return 201
先日 DDD に関する会議に出席した際に出くわした友人は「ここ10年来 ORM は使ってないよ」と言っていました。リポジトリパターンも ORM も「生」の SQL を抽象化する役割を果たしますから、一方を利用すれば他方は必要ないわけです。ORM を使用せずにここで学習しているリポジトリパターンを実装してみたらどうでしょう?
こちらの GitHub で必要なコードを取得できます。
残りの必要なリポジトリテストは読者にお任せします。どのような SQL を記述するかはあなた次第ですが、考えているよりも難しいかもしれませんし、何てことないかもしれません。ただ一度記述してしまえば、アプリケーションの他の部分でそのことを考える必要は一切なくなります。
これがリポジトリパターンを採用する最大の利点の1つでしょう:
A simple fake repository using a set (repository.py)
class FakeRepository(AbstractRepository):
def __init__(self, batches):
self._batches = set(batches)
def add(self, batch):
self._batches.add(batch)
def get(self, reference):
return next(
b for b in self._batches if b.reference == reference
)
def list(self):
return list(self._batches)
各メソッドは Batch オブジェクトを要素とする set を操作しているだけですから非常に単純です。
このような「偽の」リポジトリはテストでの利用も非常に簡単ですし、それでいながらちゃんとした「抽象化」を実現してくれます。テストでの利用はこんな感じです:
Exmaple usage of fake repository (test_api.py)
fake_repo = FakeRepository([batch1, batch2, batch3])
次章では、このような「偽の」リポジトリを利用する例をお見せします。
こういった「偽の」抽象化層の構築は、自分のシステムデザインに対する大切なフィードバックともなり得ます。もし「偽」の構築が困難であれば、それは自らの抽象化デザインが複雑過ぎる、ことの裏返しであるかもしれないからです。
この本の主題はあくまでも「依存性の逆転 (dependency inversion)」ですし、それを実現するためであればどのようなテクニックを使用しようがあまり大きな問題ではありません。ですからここで「専門用語」について深入りするつもりはありませんし、それは人によって少しずつ解釈が異なるものです。
Ports と adapters はオブジェクト指向の考え方を基にしており、我々の理解では、port はアプリケーションと抽象化対象間のインターフェースであり、adapter はそのインターフェース、もしくは、抽象化の実装、です。
Python にはインターフェース自体が存在しないため、adapter を認識するのは通常容易ですが、port を定義するのは困難な場合があります。もし抽象基底クラス (abstract base class) を利用しているのならそれは port です。もしそうでなければ port はただのダックタイプ (duck type) に過ぎません。つまりそれはただの関数/メソッド名であり、それらに渡される引数名であり、それら引数の型でしかありません。そして adapters はそれらに準拠し、コアアプリケーションはそれらに依拠することになります。
この章でやってきたことに当てはめてみれば、AbstractRepository は port であり、SqlAlchemyRepository と FakeRepository は adapters ということになります。
Rich Hickey の金言を胸に、各章の最後では、その章で取り上げたアーキテクチャパターンの長所・短所をまとめたいと思います。はっきりさせておきたいのは、全てのアプリケーションをこのようにデザインしなければならない、と言っているわけではない、ということです。アプリケーションとドメインが複雑になる可能性がある場合に、見てきたような層を追加する時間と手間をかける価値が生じる状況もある、ということです。
以下に、リポジトリパターンと、それを利用するストレージ層に依拠しない model デザインに対する主たる賛否をまとめてみました:
永続/持続ストレージと domain model 間に簡素なインターフェースを構築します。
単体テスト向けの「偽の」リポジトリを簡単に作成可能です。また、ストレージシステムの変更/交換も容易に行えます。これはすべて、model とデータ基盤層が完全に分離されているからこそ実現できるものです。
データ保持の詳細を気にせず domain model を記述することができるので、目前のビジネスの課題に集中することが可能です。もしシステムを根本的に変更する必要が出来しても、model に手を加えるだけで対処できます。同時に外部キーやマイグレーションのことを考慮する必要はありません。
model オブジェクトをどのようにデータベーステーブルにマップするか、の決定権は 100% 自分にありますから、複雑なデータベーススキーマは必要ありません。
ORM 自体がすでにある程度の「分離 (decoupling)」を実現しています。外部キーの変更は若干困難を伴うかもしれませんが、MySQL から PostgreSQL へ、といったデータベースマネジメントシステム自体の入れ替えは容易です。
ORM がやってくれているオブジェクトとデータベースのマッピングをわざわざ自分でやる必要があるでしょうか (仕事もコードも増えます)?
依存性逆転のために層 (layer) を追加することでメンテナンスコストが増加しますし、リポジトリパターンに馴染みがない Python プログラマーにとっては「なんじゃこりゃ (WTF factor) !?」的要素の追加にほかなりません。
判断基準は次の図のようになるでしょうか: 単純なケースでは、domain model と基盤部分の分離は、ORM / ActiveRecord パターンよりもコストが高くなります。
もし作成するアプリケーションがデータベースに対する CRUD (Create-Read-Update-Delete) 機能を提供するためだけのラッパーなのであれば、そもそも domain model もリポジトリも必要ありません。
しかし domain がより複雑なのであれば、基盤部分からの分離に対する「投資」は、様々な面での変更が容易になる、という意味においても十分見合うものになるはずです:
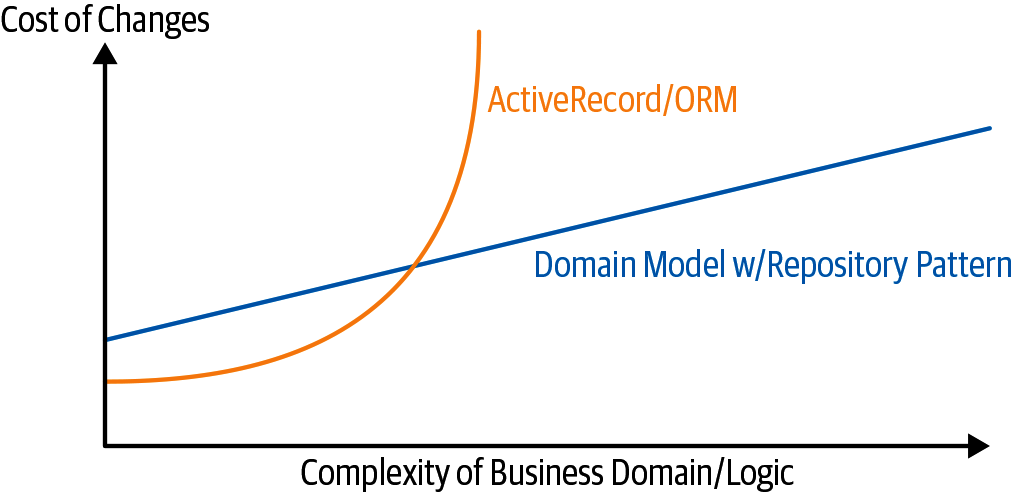
Figure 2-6. Doamin model trade-offs as a diagram
(domain model におけるリポジトリパターン vs ORM トレードオフ判断図)
- Harry Percival, Bob Gregory (March 2020). Architecture Patterns with Python. O'Reilly Media, Inc -
この章でお見せした例は、このグラフにおける右側、すなわち、domain model が非常に複雑である場合の判断基準となるほどのものではありません。しかし想像してみてもらうことは可能です。例えば後日、現在では Batch クラスで実装している allocate 操作を OrderLine クラスで実装するように変更することになったとします。もしわれわれのシステムが Django を利用しているものであれば (つまり ORM を採用していれば)、いかなるテストを行うよりも前に、まず、データベース関連の再定義、再実装に取り掛かる必要があります。しかし現状は、我々のオブジェクトはなんの変哲もない Python のオブジェクトですから、set() を新たな属性に変更することなど朝飯前です。ビジネスモデルの変更時点でデータベースのことを考慮する必要など全くありません。
Domain model が基板実装 (infrastructure concerns: データベースマッピング/処理) に依存すべきではありません。ORM 側が model をインポートするのであって、決してその逆ではありません。
リポジトリパターンは永続/持続ストレージ周りの簡易な抽象化手法です
リポジトリは、操作対象オブジェクトがすべてメモリ上に存在する、ように見せかけます。テスト用の「偽の」リポジトリを作成したり、アプリケーションのコア部分に一切変更を加えずに基盤部分をすっかり入れ替えたりすることを簡単に行うことが可能です。
ここまで読み進めてきて、「偽にせよプロダクションベースにせよ、こういったリポジトリをどうやってインスタンス化するのさ?」と思いますよね、「ここまで見てきた Flask アプリは実際どう機能するのさ?」と。それは「the Service Layer pattern (サービスレイヤーパターン)」の章で明らかになります。
でも、お楽しみの前にちょっと余談を挟みます、次へ つづく...

